Intel has also joined in: in-depth optimization for DeepSeek
On February 1st, U.S. chip giant Intel stated that Chinese AI company DeepSeek recently released the Janus Pro model. Its super performance and high accuracy have attracted the attention of the industry. Intel Gaudi 2D AI accelerator has now been deeply optimized for this model, which makes AI development Users can deploy and optimize complex tasks at lower costs and with higher efficiency.
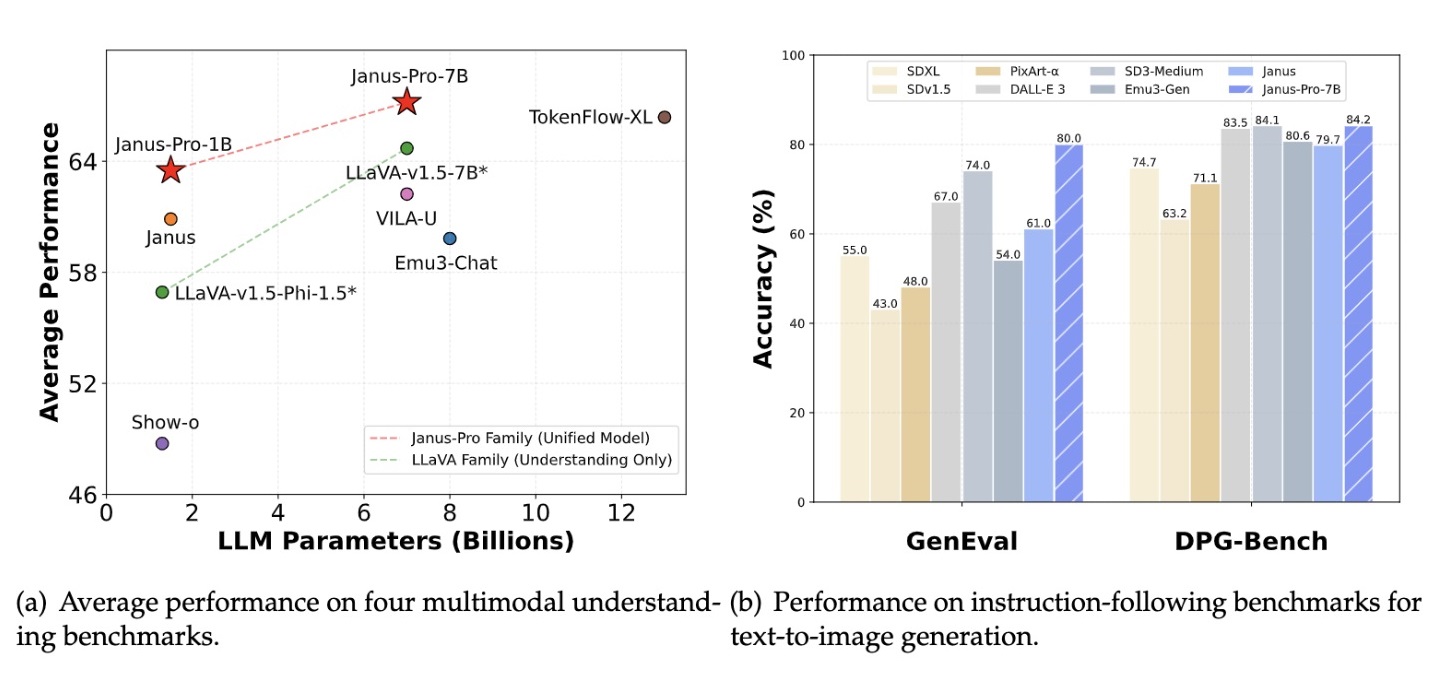
As an innovative AIGC model, the DeepSeek Janus model integrates multi-modal understanding and generation functions. This model adopts a unified Transformer architecture for the first time, breaking through the limitations of traditional AIGC models relying on multi-path visual coding, and achieving integrated support for understanding and generation tasks. On this basis, Janus Pro significantly improves the performance and stability of features such as text-to-graph generation by optimizing training strategies and expanding model size, and provides two versions with 1 billion and 7 billion parameters, demonstrating strong competitiveness in performance and accuracy.
Under the unified Transformer architecture of Janus Pro, the throughput of text-to-graph generation models has changed from relying on the high computing power of accelerators to fully utilizing the high bandwidth and large capacity of HBM memory.
Intel said that Gaudi 2D provides powerful computing support for the Janus Pro model with its high bandwidth of 2.45TB/second and large-capacity HBM memory of 96GB, allowing it to perform batch graph generation processing tasks as the batch size increase, the throughput performance is significantly improved and the task processing time is greatly shortened.
At the same time, combined with the optimization of the Intel Optimum Habana framework, Intel Gaudi 2D has significantly improved the throughput performance and reasoning efficiency of text-to-graph generation tasks, and can generate 16 high-quality images in only about 10 seconds. Moreover, developers only need to adjust a few lines of code to achieve this result, greatly reducing development barriers and migration costs. In addition, DeepSeek’s distillation model is also supported on Xeon and Gaudi platforms.
The American chip giant also mentioned that DeepSeek-R1 makes local deployment of lightweight models easier. DeepSeek can currently run on Intel products and can also be used offline on AI PCs.
Not only Intel, but NVIDIA, which has admired DeepSeek from the beginning, also announced on January 31st that the inference model DeepSeek-R1 has officially landed on NVIDIA NIM microservices. According to reports, on a single NVIDIA HGX H200 system, the full version of DeepSeek-R1 671B can process up to 3872 Tokens/second.
At the same time, Amazon also launched the DeepSeek-R1 model in Amazon Bedrock and SageMaker AI.
Microsoft, which once rushed out with OpenAI to high-profile question DeepSeek's "stealing" data, even deployed DeepSeek-R1 on its own cloud service Azure the day before.

Intel's old rival AMD also announced a week ago that it has integrated the new DeepSeek-V3 model onto the Instinct MI300X GPU. The model has been enhanced by SGLang and optimized for Al inference.